
Identificar tudo: o papel dos identificadores padrão na comunicação científica
Todd A. Carpenter, Diretor Executivo da NISO – National Information Standards Organization – apresenta um panorama dos diversos tipos de identificadores digitais e seu papel fundamental na habilitação da interligação de dados – Linked Data – em cada um dos estágios da comunicação científica. Gerenciar identificadores e metadados associados é complexo e custoso, mas é a forma mais eficiente de criar uma infraestrutura confiável de valor. Em cada uma das etapas do ciclo da comunicação científica, diversos identificadores são utilizados, conforme explicitado na figura a seguir:
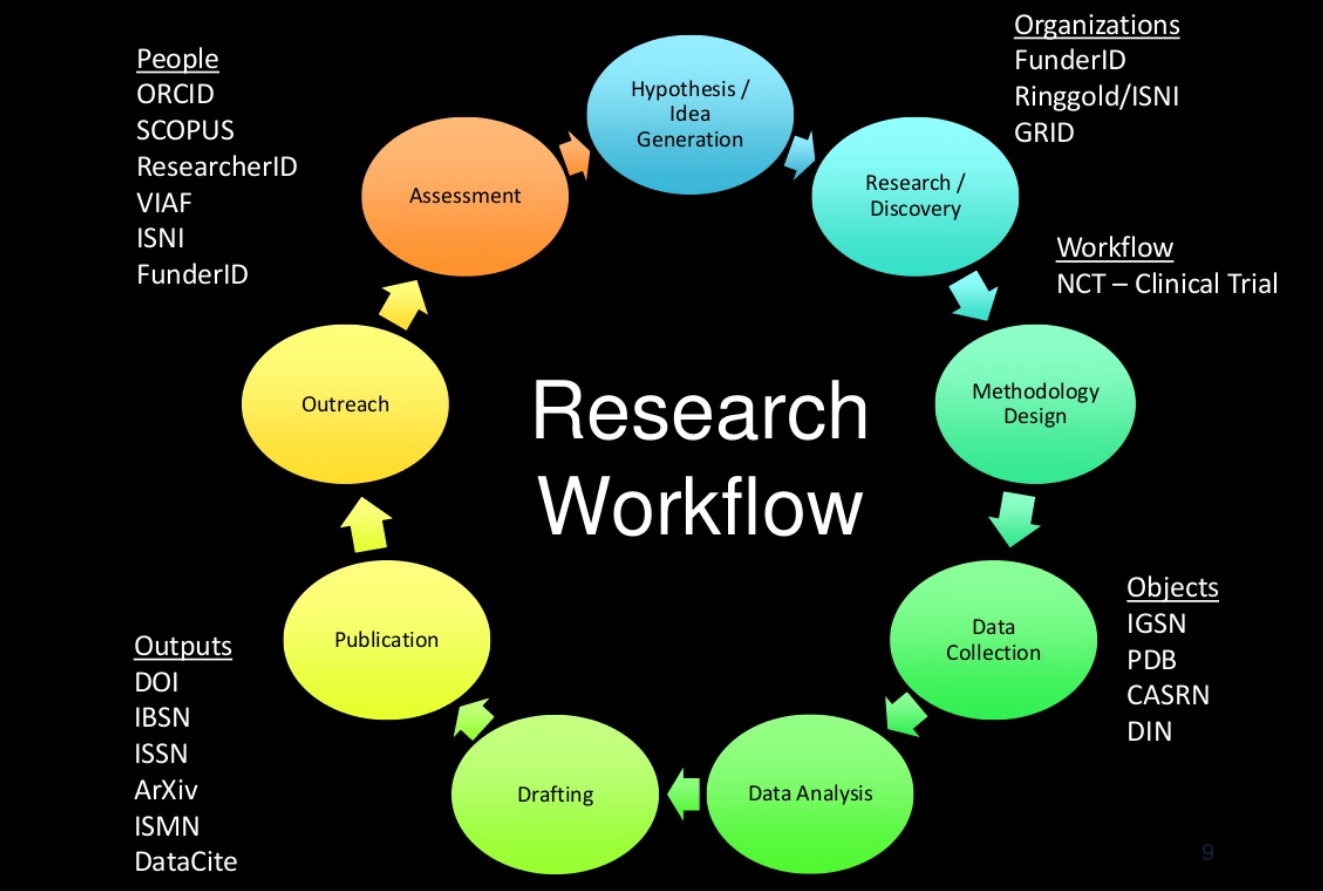
Um identificador incorpora a informação necessária para distinguir o que está sendo identificado de todas as outras coisas dentro do seu escopo de identificação. O uso do termo “identificar” tem a finalidade de distinguir um recurso de todos os outros recursos, independentemente de como esse objetivo é realizado (por exemplo, por nome, endereço ou contexto). É preciso ter cuidado para não supor que um identificador define ou incorpora a identidade do que é referenciado, embora seja esse o caso para alguns identificadores. Também não deve ser assumido que um sistema de identificação acessará o recurso identificado: em muitos casos, são usados para designar recursos sem qualquer intenção de que eles sejam acessados. Do mesmo modo, o recurso identificado pode não ser de natureza singular, pode ser um conjunto nomeado ou um mapeamento que varia ao longo do tempo. Nesse sentido, o principal papel do identificador não é desambiguar, mas habilitar a interligação de dados enriquecidos por metadados.
Confira a apresentação realizada em novembro de 2017 na Conferência “Managing Digital Research Objects in an Expanding Science Ecosystem” realizada na Biblioteca Nacional de Medicina em Bethesda, Maryland, Estados Unidos. Links para as demais apresentações estão disponíveis mais abaixo.
== Apresentação ==

== Materiais da Conferência ==
- Publicity Flyer
- Participant List
- Workshop Agenda
- Presentations
- Peter Wittenberg – “Digital Objects – the core of the complex Data Market“
- Larry Lannom – “C2CAMP“
- Brooks Hanson – “Implementing Best Practices around FAIR Data in Scholarly Publishing“
- Julie McMurry – “Identifiers for the 21st Century: Potholes, Prevention, Persistence“
- Todd Carpenter – “Identify Everything: The role of standard identifiers in communicating science“
- Patricia Cruse – “Persistent Identifiers: Glue and Connections“
- Carole Goble – “Research Objects: More than the sum of many parts“
- Lisa Kempler – “EarthCube’s Use Case Collection Project: Why we did it, what we learned“
- Dave Vieglais – “Connecting Users with Digital Research Objects“
- Danie Kinkade – “Managing Oceanographic Research Results“
- James Myers – “An Ecosystem Approach to Data Services and Digital Research Objects“
- Jim Hendler – “Respondent Thoughts“